Java并发实现原理-多线程基础-JMM与happen-before(6)
1.为什么会存在“内存可见性”问题?
要解释这个问题,就涉及现代CPU的架构。如下是x86架构下CPU缓存的布局,即在一个CPU4核心下,L1、L2、L3三级缓存与主内存的布局。每个核上面有L1、L2缓存,L3为所有核共用。
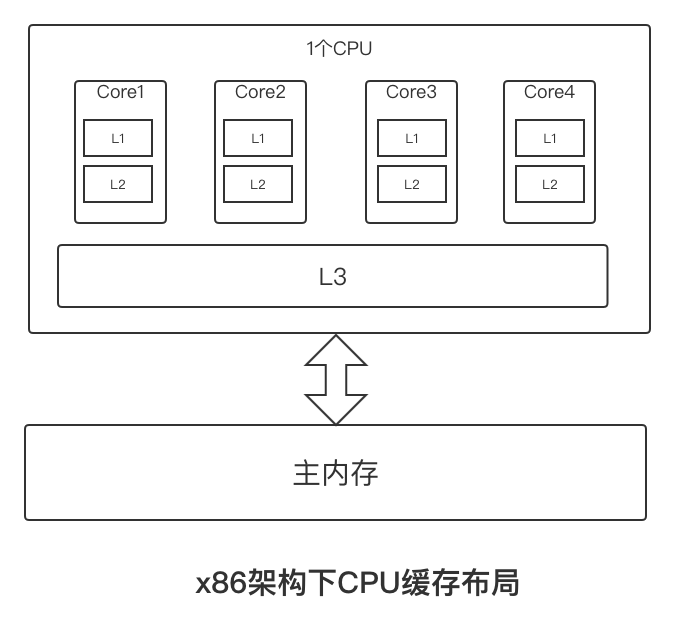
因为存在CPU缓存一致性协议,例如MESI,多个CPU之间的缓存不会出现不同步的问题,不会有“内存可见性”问题。
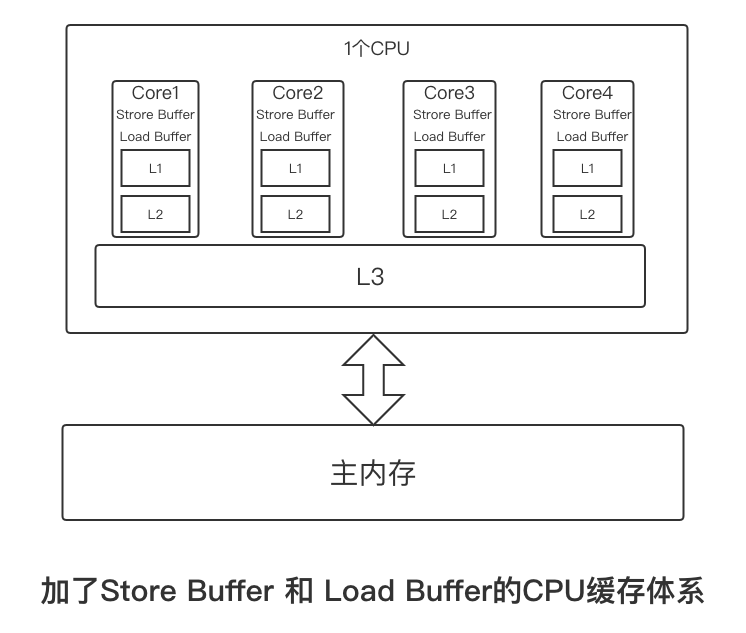
但是,缓存一致性协议对性能有很大损耗,为了解决这个问题,CPU的设计者们在这个基础上有进行了各种优化。例如,在计算单算和L1之间家林Store Buffer、Load Buffer(还有其他各种Buffer),如下图所示。
L1、L2、L3和主内存之间是同步的,有缓存一致性协议的保证,但是Store Buffer、Load Buffer和L1之间确实异步的。也就是说,往内存中写入一个变量,这个变量会保存在Store Buffer里面,稍后才异步地写入L1中,同时同步写入主内存中。
注意这里只是简要花了x86的CPU缓存体系,还没有进一步讨论SMP架构和NUMA的区别,还有其他CPU架构体系,例如PowerPC、MIPS、ARM等,不同CPU的缓存体系会有各种差异。
但站在操作系统内核的角度,可以统一看待这件事,也就是如下所示的操作系统内核视角下的CPU缓存模型。
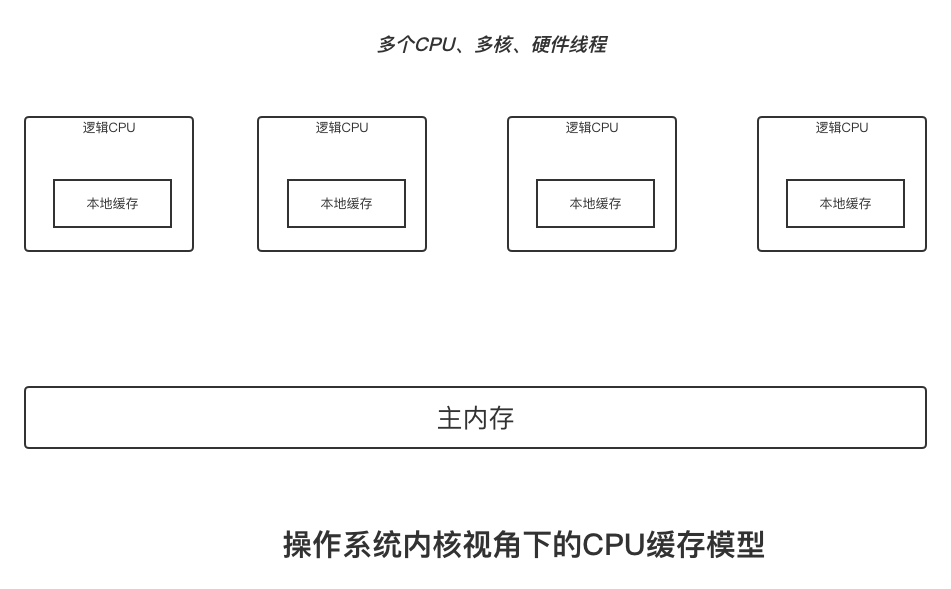
多CPU、每隔CPU多核心,每隔核心上面可能还有多个硬件线程,对于操作系统来将,就相当于一个个的逻辑CPU。每隔逻辑CPU都有自己的缓存,这些缓存和主内存之间不是完全同步的。
对应到Java里,就是JVM抽象内存模型,如下图所示。
到此为止,介绍了不同CPU架构下复杂的缓存体系,也就回答了为什么会出现“内存可见性”问题。

2.重排序和内存可见性的关系
Store Buffer的延迟写入是重排序的一种,成为内存重排序(Memory Ordering)。除此以外,还有编译器和CPU的指令重排序。下面对重排序做了一个分类:
1.编译器重排序。对于没有先后依赖关系的语句,编译器可以重新调整语句的执行顺序。
2.CPU指令重排序。在指令级别,让没有依赖关系的多条指令并行。
3.CPU内存重排序。CPU有自己的缓存,指令执行顺序和写入主内存的顺序不完全一致。
在三种重排序中,第三类就是造成“内存可见性”问题的主要原因,下面再举例来进一步说明这个问题,如下所示:
线程1:
X = 1
a = Y
线程2:
Y = 1
b = X假设X、Y是两个全局变量,初始的时候,X=0,Y=0。请问,这两个线程执行完毕之后,a和b的正确结果应该是什么?
很显然,线程1和线程2的执行先后顺序是不确定的,可能顺序执行,也可能交叉执行,最终正确的结果可能是:
(1) a = 0,b = 1
(2) a = 1,b = 0
(3) a = 1,b = 1也就是不管谁先谁后,执行结果应该是这三种场景中的一种。但实际可能是 a = 0, b = 0。

